
Why I Use Open Weights LLMs Locally
Published:
As someone who regularly uses Large Language Models (LLMs) for personal use and builds apps with LLMs - the choice between self-hosted open weights LLMs and proprietary LLMs is a recurring theme. Here, I share my personal insights as to why I use locally hosted LLMs. As a disclaimer, I still use ChatGPT’s GPT-4 and GitHub Copilot for certain use cases and have not completed weaned off them yet.
Although LLMs such as Meta’s Llama2 are frequently referred to as open-source LLMs, a more precise term would be open weights LLMs. This terminology is important to note because the underlying code that generates these models is typically not disclosed. Nonetheless, the two terms are often used interchangeably.
Removing censorship and using the full creativity of LLMs
You’ve likely noticed that proprietary models are highly censored, limited, and biased due to alignment - to reduce harmful and toxic responses. You’ll often get responses such as “As a large language model created by OpenAI…” and caveats such as “It’s important to note…”.
Now this is not an inherently bad, but sometimes the LLM may refuse to fulfil a task even if it seems reasonable, or it may simply not infer on certain topics. By using open weights LLMs you can get more creative, useful, and non-biased responses on all topics.
Limitation example of a proprietary LLM. Source
No need to share your data with big tech companies
In general, I avoid sharing my data with others when I don’t need to, especially if the data is sensitive for personal or work reasons. In OpenAI’s data retention policy they do not guarantee to not read your data. Do you want companies to profit off of your work and code and sell back to you models that are trained on your data?
I’d rather not manually anonymise and redact sensitive information from my queries and documents every time I use an LLM. With locally hosted LLMs you can be safe in knowledge that your work and data remains confidential and stays on your machine. Data privacy and security are key reasons why I use local LLMs.
Customising tools to fit your needs
Hosting an LLM on your own computer gives you greater control over the setup, configuration, and customisation options. You can tailor the LLM to your specific needs, experiment with different settings, and integrate it into your existing infrastructure.
Since LLMs are stateless, you can swap between any of the 500K models available from HuggingFace whenever you want. So you can use different models for different tasks.

Some popular open weights LLMsSource
Although proprietary LLMs, like GPT-4, may have higher performance compared to open weights models, like Llama2 or Mixtral, according to leaderboards - these benchmark tasks are likely not specific to your task or domain. You can easily fine tune these models to get better performance for your specific task.
Since open-source development is much more agile than commercial development, local inference stacks can offer cutting-edge features not yet available in commercial services, such as llama.cpp’s Grammars feature.
This means you will need to manage models, prompts, memory, and external knowledge with Retrieval Augmented Generation (RAG), which requires some effort on your part. However, this is becoming increasingly easier with many open-source solutions which abstract these components, which I will discuss in a future post.
Nevertheless, self-hosting an LLM is a great learning experience and a fun and rewarding endeavour - understanding how this rapidly evolving technology works. By understanding and owning these tools, you can decide on how you use them.
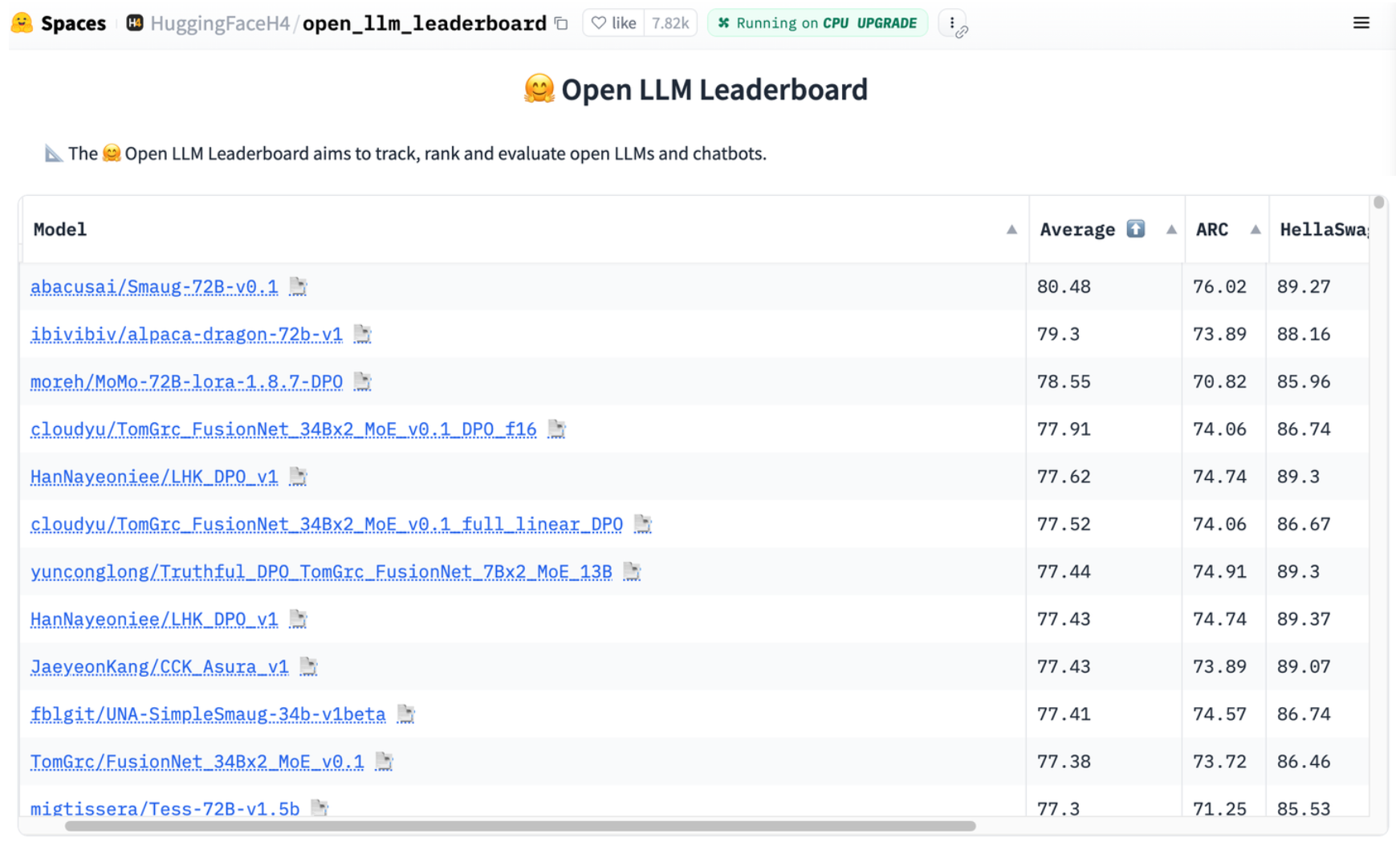
HuggingFace Open LLM Leaderboard. Source
Local LLMs provide more reliable and consistent outputs
Using proprietary LLMs requires an internet connection, whereas a locally hosted LLM will work in “offline mode” without the internet or if a proprietary provider’s service is shut down. You have resiliency should these services fail or go out of business.
Locally hosted LLMs provide constant and predictable response times compared to API-based services. Latency responses from local LLMs can be faster than calling an API, depending on your hardware, model selection, and network.
Commercial services are constantly changing and these updates, for better or for worse, are not transparent. The response you get from a proprietary model will be different compared to yesterday’s - and you will have no idea why. You do not get this unpredictability with local models. Local LLM systems are more deterministic.
Significant cost savings from switching to local LLMs
By using self-hosted LLMs, you do no need to pay for subscriptions or API call charges. Another issue with proprietary LLMs is vendor lock in. You will always be at the mercy of the provider changing their pricing policies.
As an individual user, you’ll likely be saving money despite the increase in electricity usage from the high (V)RAM and CPU usage but this depends on your utility provider’s electricity costs.
For business use cases it makes even more sense to switch away from proprietary LLMs. Paying per X tokens does not scale for businesses and is only useful either as a proof-of-concept or for very high return use cases. Even with better responses, paying more with API calls will lead to lower ROI. Not to mention the extortionate costs of fine tuning on cloud platforms.
If you do use OpenAI’s model and libraries to develop your GenAI applications, in Ollama’s latest update you can reuse your existing OpenAI code and simply switch the model API to call your locally hosted one.
Conclusion
My transition to locally hosted LLMs has been a fun shift, enhancing my work with increased creativity, data privacy, and customisation, while also offering significant cost reductions. As I continue to explore this space, the value of local hosting of LLMs becomes more apparent.
In my next blog post I’ll share how you can locally host and run these open weights LLMs using open-source solutions.
Enjoying the content? Follow me on Medium or support my work with a coffee!